
반응형
Nan = Not a number = 결측치
Nan
df.decribe() - count, 50%(median)
df.describe()
- count : 결측치가 아닌 값들의 개수
- age_50% : 모든 승객의 50%가 28세 미만, 나머지 50%가 28세 이상
데이터 자료형이 객체(object)인 열 선택하고 싶을 때
df.describe(include ='O')
: 모든 열에 대해 데이터 자료형이 객체(object)인 열을 선택할 수 있음
매개변수 정보 불러오기
Shift + Tab : 메소드에 대한 모든 매개변수 정보를 볼 수 있다.
Shift + Tab*2 : 매개변수에 대한 더 자세한 정보
Shift + Tab*3 : 매개변수에 대한 더 자세한 정보 + 입력하는 동안 n초 켜져 있음
Shift + Tab*4 : tooltip창이 완전히 열림
Series, DataFrame
df['col1'] -- 시리즈 형태
df[['col1']] -- 데이터프레임 형태
데이터 불러올 때, 인덱스 설정
df = pd.read_csv('df.csv', index_col = 'col1'): 인덱스로 설정하고 싶은 열 설정하기
같은 값을 반환하고 있는지 확인 작업
df.iloc[:,4].equals(df.col1)
iloc[] vs. loc[]
iloc[포함:미포함]
loc[포함:포함]
df.reindex()
df.reindex(index=[0, 5, 30000, 40000], columns=['Athlete', 'Medal', 'Age'])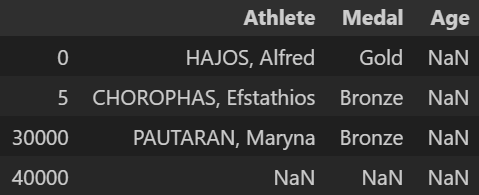
: 없는 값들은 결측치로 채워넣어진 채로 출력됨
df['col1', 'col2'] 보다는 df.loc[:, ['col1', 'col2']]
df.loc[:,['col1', 'col2']]
chained indexing 하지 않기
df.loc['a', ['col1', 'col2', 'col3']]
-- 아래는 chained indexing
df['col1', 'col2', 'col3']].loc['a']
df.loc['a'][['col1', 'col2', 'col3']]
index로 설정한 열은 iloc에서 포함 x
df.iloc[:,0]
첫 5개 행, 354, 765행 불러오기
rows = list(range(5)) + [354, 765]
df.iloc[rows]
첫 3개 칼럼, Gender, Event 칼럼 불러오기
col = df.columns[:3].to_list() + ['Gender', 'Event']
df.loc[:, col]
200, 300번째 행과 Athlete, Medal 칼럼 불러오기
df.loc[[200, 300], ['Athlete', 'Medal']]
'PHELPS Michael'행의 칼럼 4, 6 불러오기
col = df.columns[[4, 6]]
df.loc['PHELPS, Michael', col]
반응형