
01 옵티마이저와 실행계획
1. 옵티마이저 : 최적의 실행계획을 결정하는 것
- SQL문에 대해 최적의 실행방법(계획)을 결정한다.
- 관계형 DB는 옵티마이저가 결정한 실행 계획대로 처리해 결과를 사용자에게 전달한다
=> 옵티마이저의 실행 계획은 수행 속도에 가장 큰 영향 미침
▷옵티마이저 엔진
- 질의 변환기(Query Transformer) : 작성된 SQL문을 처리하기 용이한 형태로 변환하는 모듈
- 비용 예측기(Estimator) : 생성된 계획의 비용을 예측하는 모듈
- 대안계획 생성기(Plan Generator) : 동일한 결과 생성하는 다양한 대안 계획 생성하는 모듈
① 연산 적용 순서
② 연산 방법
③ 조인 순서의 변경 통해 대안 계획 생성
▷종류
| 규칙기반 옵티마이저 Rule Based Optimizer |
비용기반 옵티마이저 Cost Based Optimizer |
|
| 실행계획 생성방법 |
SQL문의 인덱스 유무, 연산자 종류, 참조객체 등의 정보에 따라 우선순위가 정해져있고, 우선순위 기반으로 실행계획 생성 우선순위가 높은 규칙이 적은 일량으로 작업을 수행하는 것이라 판단하는 것 1. ROW ID를 사용한 단일 행인 경우 2. 클러스터 조인에 의한 단일 행인 경우 3. 유일하거나 PK를 가진 해시 클러스터 키에 의한 단일 행인 경우.. |
SQL문을 처리하는데 필요한 비용(소요시간, 소요 자원등)이 가장 적은 실행계획을 선택한다. 현재는 대부분 비용기반 옵티마이저만 제공한다. 비용을 예측하기 위해 규칙기반 옵티마이저가 사용하지 않는 각종 통계정보를 참고한다. (=정확한 통계정보를 유지) |


*SQL문 실행 순서
① 파싱(Parsing) : SQL 문법 검사 및 구문 분석 작업
② 실행(Execution) : 옵티마이저의 실행 계획에 따라
③ 인출(Fetch) : 데이터 읽어 전송
2. SQL 처리 흐름도 : SQL문의 처리절차를 시작적으로 표현한 도표

3. 실행계획
SQL에서 요구한 사항 처리하기 위한 절차와 방법 나타낸다.
| 실행계획 구성요소 |
조인 순서 | 조인작업 수행 시 참조하는 테이블 순서 |
| 조인 기법 | 두 테이블을 조인할 때 사용하는 방법. NL JOIN, HASH JOIN, SORT MERGE JOIN 등 | |
| 엑세스 기법 | 한 테이블을 엑세스할 때 사용할 수 있는 방법. INDEX SCAN, FULL TABLE SCAN 등 | |
| 최적화 정보 | 각 단계마다 예상되는 비용사항 비용사항이 표시된 것은 비용기반 최적화 방식으로 실행계획을 세웠다는 것을 의미하고, COST(상대적인 비용정보), CARD(조인을 만족한 집합의 건수), BYTES(결과집합이 차지하는 메모리 양)가 있다. |
|
| 연산 | 여러 조작을 통해 원하는 결과를 얻어내는 일련의 작업 |
Q. 옵티마이저와 실행계획에 대한 설명으로 부적절한 것을 2개 고르시오.
① SQL 처리 흐름도는 성능적인 측면의 표현은 고려하지 않는다. // 성능측면도 표현할 수 있다.
② 규칙 기반 옵티마이저에서 제일 높은 우선순위는 행에 대한 고유주소를 사용하는 방법이다.
③ SQL처리 흐름도 인덱스 스캔 및 전체 테이블 스캔 등의 액세스 기법을 표현할 수 있다.
④ 인덱스 범위 스캔은 항상 여러 건의 결과가 반환된다. // 결과 건 수 만큼 반환하지만, 결과가 없으면 한 건도 반환하지 않을 수 있다.
02 인덱스 기본
1. 인덱스(찾아보기)
: 원하는 데이터를 쉽게 빠르게 찾을 수 있도록 하는 '찾아보기'와 유사한 개념
: 테이블 기반으로 선택적으로 생성할 수 있고, 여러 개 생성 가능
: 단, DML작업은 테이블과 인덱스를 함께 변경해야하기 때문에 오히려 느려질 수 있다.
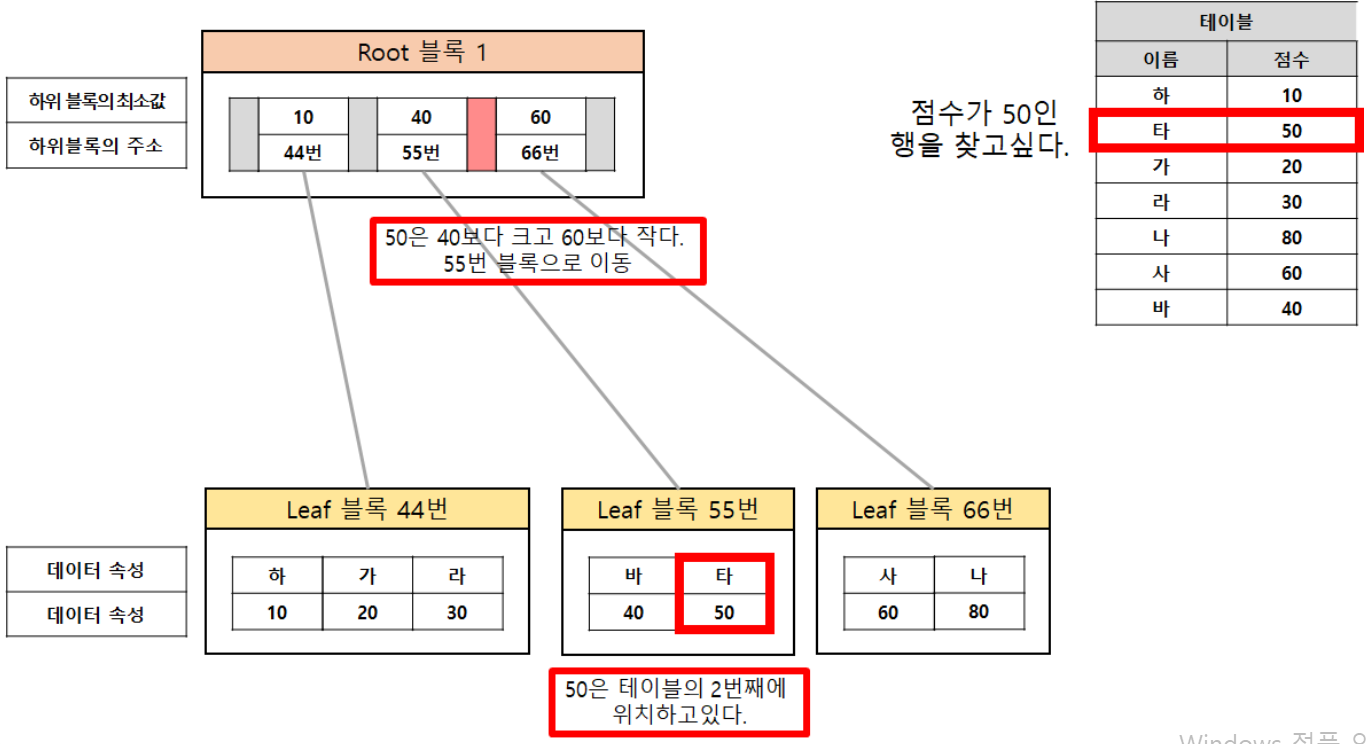
▷ B-TREE 인덱스 : 가장 일반적인 인덱스
| Root Block | 루트 블록. 가장 최상위에 위치한 블록 |
| Branch Block | 브랜치 블록. 다음 단계 블록을 가리키는 포인터를 가지고 있다. |
| Leaf Block | 리프 블록. 가장 하위에 위치한 블록. 인덱스 데이터는 칼럼값, RID(Row ID)순서로 정렬된다. 양방향링크를 가지고 있어 오름차순, 내림차순 검색이 쉽다. |
*ROWID : Oracle에서 데이터를 구분할 수 있는 유일한 값, 데이터 입력하면 자동으로 생성됨, 데이터가 어떤 데이터 파일의 어느 블록에 속해 있는지 알려줌


▷ SQL Server의 클러스터형 인덱스(저장구조에 따른 분류)
| 구분 | 클러스터드 인덱스 | 넌클러스터드 인덱스 |
| 공통점 | 둘다 B-TREE 방식 이용 | |
| RID 필요여부 | 리프 페이지 = 데이터 페이지 → 따라서 탐색에 필요한 RID 필요X |
데이터의 위치정보(RID)를 인덱스로 구성 |
| 정렬 | 인덱스 칼럼으로 인덱스도 정렬 테이블의 데이터도 정렬 |
인덱스 칼럼으로 인덱스만 정렬 테이블의 데이터는 그대로 |
| 인덱스 수 | 테이블 당 1개 인덱스 생성 가능 | 테이블 당 여러 개의 인덱스 생성 가능 |
| 검색 속도 | 빠르다 | 느리다 |
| 인덱스 공간 | 적게 차지한다 | 많이 차지한다 |

▷ 인덱스 생성
CREATE INDEX 인덱스명 테이블명 ON 테이블명(칼럼명, ...)*인덱스 키가 변환되면 사용 불가
ex) NVL(인덱스키, 값), TO_타입(인덱스키), 인덱스키||값
2. 인덱스 스캔 효율화
: 랜덤 액세스 최소화(인덱스 스캔 후 추가 정보를 가져오기 위한 랜덤 엑세스는 DBMS 성능부하 유발)
*인덱스 칼럼의 순서는 랜덤 엑세스와 부관
3. 스캔 방법
| 구분 | FULL TABLE SCAN(전체 테이블 스캔) | INDEX SCAN(인덱스 스캔) |
| 설명 | 모든 데이터 읽어가며 조건에 맞으면 추출, 조건에 안맞으면 버리는 방식으로 검색 재사용성이 떨어지며, 블록들이 메모리에서 곧 제거될 수 있도록 관리 따라서 SQL문에 조건이 존재하지 않는 경우, 조건에 사용가능한 인덱스가 존재하지 않는 경우 등에 사용 |
인덱스 구성하는 칼럼의 값을 기반으로 데이터 추출하는 엑세스 기법 인덱스에 존재하지 않는 칼럼의 값이 필요한 경우, 현재 읽은 RID를 이용해 테이블에 엑세스 해야 함 = 사용 가능한 인덱스가 존재해야 사용가능 인덱스 구성 칼럼의 순서, RID로 정렬됨 데이터 읽으면 결과도 정렬되어 반환 |
| 모든 테이블의 위치 알고서 데이터 읽음 = 불필요하게 다른 데이터 읽어야 함 = 한 요청에 여러 블록 읽음 |
인덱스에 존재하는 RID를 이용해 검색하는 데이터의 정확한 위치를 알고서 데이터 읽음 = 불필요하게 다른 데이터를 읽을 필요 없다 = 한 요청에 한 블록 씩 읽음 |
|
| 테이블의 대부분의 데이터를 찾을 때 효과적 | 테이블의 일부 데이터를 찾을 때 효과적 |

4. IOT(Index-Organized Table) : 인덱스 키가 붙은 칼럼으로 구성된 테이블, 인덱스가 원래 테이블을 참조하지 않음, 클러스터형 인덱스와 유사함
03 조인 수행원리
1. 조인 순서 : 항상 두 테이블을 조인함
▷ 선행 테이블(First Table, Outer Table, Driving Table, Build Input)
▷ 후행 테이블(Second Table, Inner Table, Driven Table, Probe Input) : 선행 테이블로부터 입력값 받아 처리, 후행 테이블에 걸리는 조인 조건이 성능에 큰 영향 미침
2. 조인 방식 : NL조인 > 소트 머지 조인 > 해시 조인 순서로 발전
| 구분 | Nested Loop Join | Sort Merge Join | Hash Join |
| 조인 방법 | 선행 테이블의 결과를 추출, 후행 테이블을 읽으면서 조인 수행 (중첩된 반복문과 유사) 선행 테이블의 조건을 만족하는 행 수만큼 반복됨 조인 성공하면 바로 결과 보여줄 수 있다. |
조인 칼럼을 기준으로 테이블을 정렬하여 조인 수행 조인할 테이블이 이미 정렬되어 있다면 정렬 작업은 발생하지 않을 수도 있다. |
조인 칼럼을 기준으로 해쉬함수 수행해 서로 동일한 해쉬값 갖는 것들 사이에서 실제 값이 같은지를 비교하며 조인 수행 NL join의 랜덤 액세스 문제점과 Sort Merge Join의 정렬 작업 부담 해결의 대안으로 등장 CPU연산 많이해 충분한 메모리 공간 필요 |
| 조인 제한 | 동등조인, 비동등조인에서 사용 가능 | 동등조인에서만 사용 | |
| 데이터 읽는 방법 | 랜덤 엑세스 방식 | 스캔 방식 | |
| 처리 범위 | 좁은 범위가 유리 | NL조인에서 부담되던 넓은 범위의 데이터를 처리할 때, 이용된다. (그러나 정렬 많아지면 성능 떨어질 수 있다.) | 정렬작업이 없어 정렬이 부담되는 대향 배치작업에 유리 |
| 동작방법 | - 선행 테이블에서 주어진 조건을 만족하는 행 찾음 - 선행 테이블의 조인 키 값을 가지고 후행 테이블에서 조인 수행 - 선행 테이블의 조건 만족하는 모든 행에 대해 1번 작업 반복 수행 |
- 선행 테이블 조인 키 기준으로 정렬 작업 수행 - 후행 테이블 조인 키 기준으로 정렬 작업 수행 - 정렬된 결과 이요해 조인 수행해 조인에 성공하면 추출버퍼 넣음 |
- 선행 테이블에서 조인 키를 기준으로 해쉬함수 적용해 해쉬 테이블 생성 - 후행 테이블에서 조인 키 기준으로 해쉬함수 적용해 해당 버킷 찾음 - 조인에 성공하면 추출버퍼에 넣음 - 후행 테이블의 조건 만족하는 모든 행에 대해서 반복 수행 |


