
01 비정형 데이터
- 데이터 유형
- 정형 데이터 : RDBMS, CSV 등
- 반정형 데이터 : 형태(스키마, 메타데이터 등)가 있고, 연산 불가. 보통 API 형태로 제공. XML, HTML, JSON 등
- 비정형 데이터 : 형식이 정해지지 않은 데이터. 구조화 형태 다르고 정형화되지 않은 문자, 음성, 이미지 등. 주로 NoSQL에 저장. 소셜 데이터, 영상, 이미지 등
- 비정형 데이터 종류 : 텍스트, 이미지, 음성 및 영상, 로그 등
- 분석기법
- 비정형 데이터 마이닝 - 비정형 데이터를 정형데이터로 만든 후, 분류, 군집화, 회귀분석과 같은 방법론 적용
- 텍스트 마이닝, 오피니언 마이닝, 사회연결망 분석, 군집 분석 등
02 텍스트 마이닝
1. 텍스트 마이닝 개요
- 다양한 형태의 문서로부터 텍스트 획득하고, 문서별 단어의 행렬 만들어 분석 수행하거나 인사이트 발견하는 것
- 여러 포맷의 문서에서 텍스트 추출해 하나의 레코드 만들고 단어 구성에 따라 데이터 마트 구성
- 단어 간의 관계 활용해 감성 분석, 워드 클라우드 등 수행하고 정보화, 분류, 소셜 네트워크 분석 등에 활용
- 텍스트 마이닝은 문서 분류(테마별 분류, 지도 학습), 문서 군집(성격 유사한 문서끼리 그룹화, 비지도 학습), 정보 추출하고자 자연어 처리 NLP, 컴퓨터 언어학 활용
2. 텍스트 마이닝 프로세스
: 수집 > 전처리 > 분석 > 시각화 순
1. 텍스트 수집 : 텍스트 저장소에서 다운로드 or 웹페이지 크롤링
~ 코퍼스 Corpus : 데이터 정제, 통합, 선택, 변환 과정 거치고 구조화된 텍스트 데이터. 데이터 마이닝에 활용 가능. R의 텍스트 마이닝 패키지, tm에서 문서 관리하는 기본 구조
2. 텍스트 전처리 : 코퍼스의 복잡성 줄이는 것이 핵심
① 토큰화 : 코퍼스에서 토큰이라 불리는 단위로 나눈 작업
~토큰의 단위 : 어절, 형태소(뜻을 가진 가장 작은 단위), 음절
- 단어 토큰화 : 토큰 기준을 단어로 해 문자 부호 제거
- 어절 토큰화 : 토큰 기준을 어절 word segment로 해 띄어쓰기 기준으로 잘라냄. 한국어와는 맞지 않음
- 형태소 토큰화 : 형태소 morpheme이 토큰 기준. 한국어에서 영어 단어 토큰화와 유사하게 처리하려면 형태소 토큰화를 수행해야 함. 조사 분리 필요
- 품사 태깅 : 단어의 의미를 제대로 파악하고자 각 단어의 품사 구분
② 불용어 처리 Stopword Removal : 데이터에서 유의미한 단어 토큰만 사용하고자 무의미한 단어를 제거하는 것. NLTK에서는 100여개 영단어를 패키지에서 미리 정의
③ 정제 & 정규화
- 정제 Cleansing : 코퍼스에서 노이즈 제거하는 것. 토큰화 단계에서 지속적으로 진행됨
- 정규화 Normalization : 표현 방법이 다른 단어 통합시켜 표현
*표기가 다른 단어 통합, 대소문자 통일, 불필요 단어 제거, 정규 표현식 등
④ 어근 & 어간 추출 : 코퍼스 단어 수 줄이는 기법
- 어근 Lemma : 단어의 기본형 ex) am, are, is → be동사
- 어간 추출 Steming : 정해진 규칙만으로 단어를 잘라내는 어림짐작의 작업. 어근 추출에 비해 섬세함이 떨어짐
⑤ 텍스트 인코딩 : 문서를 유의미한 숫자의 행렬(벡터)로 바꾸는 것
- 원 핫 인코딩 One-Hot Encoding
- 텍스트 내 n차원의 단어를 각각 n차원의 벡터로 표현하는 방식. 각 단어에 고유한 정수 인덱스 부여
- 단어가 포함되는 인덱스에 1, 나머지에 0 넣어 표현한 벡터를 원 핫 벡터라고 함. (0, 0, 1, 0, 0)
- 단어가 증가할수록 벡터의 저장 공간이 커지고 단어 유사도를 표현하지 못하는 한계
- 말뭉치 Bag of Word
- 단어의 등장 순서를 감안하지 않고 각 인덱스 위치에 단어 토큰의 등장 횟수를 적은 벡터 생성
- 단어의 빈도를 수치화하기에 해당 문서의 성격, 주제를 판단하는 작업에 적합. 추천에 활용
- TF-IDF(Term Frequency-Inverse Document Frequency)
- 각 단어의 중요도라는 개념을 가중치로 부여. 가중치는 TF-IDF로 계산
- TF(t, d) : 문저 d 내의 각 단어 t의 빈도
- IDF(t, D) : 단어 t가 등장한 문서 D의 역수
- 워드 임베딩
- 단어를 벡터로 바꿔주는 모델
- 분산표상(비슷한 분포를 가진 단어의 주변 단어도 비슷한 의미를 지님) 개념 적용
- 원핫인코딩과 다르게 한 단어가 미리 정의된 차원에서 연속형의 값을 갖는 벡터로 표현되어 필요한 벡터 공간이 적고, 각 차원이 정보를 갖고 있어 벡터 간 유사도 도출 가능
*00년대, NNLM 방법론 → 2013, 구글 Word2Vec 방법론
3. 텍스트 분석
: 전처리가 끝나면 복합명사, 신조어 등에 대한 후처리 절차를 거쳐 데이터 분석 및 시각화 시행
① 토픽 모델링
- 문서에 담긴 여러 주제 찾는 기법
- 의미 연결망 분석 SNA 중 하나
- 텍스트 내 단어 빈도 분석해 전체 데이터 관통하는 잠재적 토픽을 자동으로 추출하는 분류 진행하기에 잴점(프레임) 분석에 활용됨
- LDA, ATM 등의 방법이 있음
② 감성 분석
- 문장에서 주관적 감정 나타내는 정보 찾아 성향 분석하는 것
- 입력된 긍/부정 단어 개수 따라 문장 성격 판단
- 대규모 웹 문서가 필요해 자동화된 분석 방법 사용
- 제품, 브랜드에 대한 선호도 파악
- 오피니언 마이닝에 필수적 분석 기술
- 버즈 모니터링 : 온라인에서 특정 테마에 대한 여론 분석하는 것. 기업에서 SNS 댓글 실시간 분석함
③ 텍스트 분류
- 텍스트를 지정한 카테고리로 분류하는 지도학습 기법
- 과거 머신러닝(SVM등)을 많이 사용했으나 최근에는 딥러닝(CNN, RNN 등) 기법을 활용하는 추세
④ 텍스트 군집화
- 벡터 연산으로 단어 벡터 간 유사도 구하고 이를 토대호 비슷한 의미 지닌 단어가 가깝게 모여 군집 형성 가능
5. 텍스트 시각화
- 워드 클라우드 : 텍스트 데이터의 특징 도출하기 위해 활용
- 의미 연결망 분석 : 문서에 있는 단어의 구조적 관계로 의미 분석하는 것. 정보 단위가 되는 단어 or 구를 각각의 노드를 이루는 개념으로 간주. 개념 간 연결 상태를 링크로 표현
- 정제된 데이터 빈도 계산해 키워드 선정하고 매트릭스 데이터로 만들어 의미 연결망 분석에 활용(R에서는 TermDocumentMatrix를 씀)
3. 정보 검색의 적절성
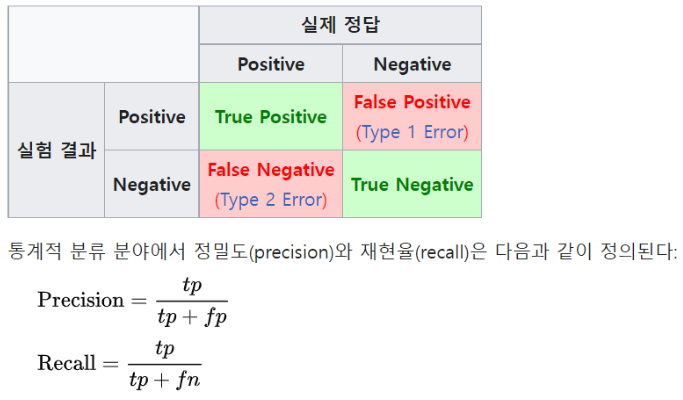
: 정보 검색 혹은 자연어 처리에서 분석 결과를 평가하는 척도로 정확도, 재현율 사용
- 정확도 Precision : 모델이 참이라고 예측한 결과 중 실제로 참인 경우의 비율
- 재현율 Recall : 실제로 참인 것 중 모델이 참이라고 예측한 결과의 비율
03 사회연결망 분석
- 정의 : 개인과 집단 간 관계를 노드와 링크로 모델링하여 분석하는 방법론. 개인 or 집단이 하나의 노드, 노드 사이의 연결은 선으로 표현
- SNA 분류
- 집합론적 방법 : 객체 간의 관계를 쌍으로 표현
- 그래프 이론을 이용한 방법 : 객체를 점으로 표현, 연결은 두 점을 연결하는 선으로 표현
- 행렬 이용한 방법 : 객체를 행과 열에 대칭하게 배치. 객체 사이 관계 있으면 1, 없으면 0
- 준연결망 quasi network : 고객-상품행렬에서 상품 구매자 간의 관계 없어도 인위적으로 설정해 고객 간, 상품 간의 관계 나타낸 네트워크
- 네트워크 구조 파악 기법
- 중심성 : 연결 정도 중심성(한 점에 직접 연결된 점들의 합), 근접 중심성, 매개 중심성, 위세 중심성(보나시치 권력지수 - 위세 중심성의 일반적 형태)
- 밀도, 구조적 틈새, 집중도도 있음
- SNA 적용
- 통신, 소셜 미디어, 게임 산업에서 관심 높음
- 분석용 솔루션으로 KXEN, SAS, XTRCT 등이 있고 MapReduce라는 분산 처리 기술 활용하거나 하둡 기반의 Giraph로 SNA 적용함
- 단계 : 그래프 생성 > 그래프 가공, 분석 > 커뮤니티 탐색 & 객체(노드)의 역할 정의 > 결과를 데이터화하여 타 데이터 마이닝 기법과 연계
*데이터화 : SNA로 입수한 커뮤니티 프로파일을 고객 연령, 성별 등과 같은 고객 프로파일 평균값으로 산출하고 고객 속성에 그룹 넘버와 룰을 결합하는 방법으로 이루어지고 있음
- R에서의 SNA
- 네트워크 레벨 통계량 : degree, shortest paths 등
- 커뮤니티 수 측정 community detection
- WALKTRAP 알고리즘 : 각 버텍스 vertex(꼭지점)를 하나의 커뮤니티로 간주해 더 큰 그룹 병합하며 클러스터링
- Edge Betweenness method : 그래프의 최단거리 중 몇 개가 edge(연결)를 거치는지를 근거로 edge-betweenness점수 측정. 이 점수가 높은 edge가 클러스터를 분리하는 속성을 가짐
#library
#install.packages("igraph")
library(igraph)
tomo <- graph.data.frame(data); tomo
summary(tomo)
vcount(tomo) #--- Vertex 노드의 수
V(tomo) #--- Vertex
ecount(tomo) #--- Edge 선의 개수
E(tomo) #--- Edge
get.edge.attribute(tomo, "friend_tie") #--- Edge attribute
get.edge.attribute(tomo, "social_tie") #--- Edge attribute
get.edge.attribute(tomo, "task_tie") #--- Edge attribute
mFriend <- delete.edges(tomo, E(tomo)[get.edge.attribute(tomo, name = "friend_tie") == 0])
mSocial <- delete.edges(tomo, E(tomo)[get.edge.attribute(tomo, name = "social_tie") == 0])
mTask <- delete.edges(tomo, E(tomo)[get.edge.attribute(tomo, name = "task_tie") == 0])
summary(mFriend)
plot(mFriend)
mFriend <- as.undirected(mFriend, mode = "collapse") #--- 방향이 없는 그래프로 변경
mFriend <- delete.vertices(mFriend, V(mFriend)[degree(mFriend) == 0]) #--- 고립되어 있는 노드를 네트워크에서 제거
summary(mFriend)
plot(mFriend)
# walktrap
mFriend_wt <- walktrap.community(mFriend, steps = 200, modularity = TRUE)
plot(as.dendrogram(mFriend_wt, use.modularity = TRUE))
mFriend_wt$modularity
# Edge Betweenness method
mFriend_eb<-edge.betweenness.community(mFriend)
plot(as.dendrogram(mFriend_eb, use.modularity = TRUE))

예상문제 대비
- 데이터 종류
- 비정형 : 형태 없음, 연산 불가
- 반정형 : 형태 있음, 연산 불가
- 웹 마이닝 종류 : 웹 내용, 웹 사용, 웹 구조 마이닝 등
- 사회 연결망 분석 SNA
- 주요 속성 : 응집력, 명성, 구조적 등위성, 범위, 중계 등
- 분석 방법 : 집합론(쌍), 그래프, 행렬
- 최근에는 독립 네트워크 사이의 관계에 대한 연구가 활발
- 1원 모드 매트릭스 : 행과 열 같은 개체가 배치된 매트릭스
- 중심성 측정 방법 : 연결 정도, 위세, 근접, 매개 중심성
- VCorpus (short for Volatile Corpus) : 메모리에서만 텍스트 문서 유지, 관리
- 텍스트 마이닐
- 기능 : 문서요약, 문서분류, 문서군집, 특성추출
- TDM-Sparcity : 0인 원소가 차지하는 비율
- 순서 : 토큰화 > 불용어 설정 > 정제, 정규화 > 어근, 어간 추출 > 인코딩
- 원핫인코딩 : 문서를 유의미한 숫자의 행렬로 바꾼 것, 각 단어에 고유한 정수 인덱스 부여
- 감성분석
- 개별 문장 분석에 오류가 있다면 전체적인 추이 파악 난이도 상승
- 텍스트 내용의 객관성 따지지 않고, 긍부정 여부만 집중