
01 표준 조인
1. SQL에서의 연산
| 종류 | SQL기능 | 설명 | |
| 집합 연산 | UNION | UNION UNION ALL |
합집합 (UNION ALL은 중복제거X, 정렬X) |
| INTERSECTION | INTERSECT | 교집합 | |
| DIFFERENCE | MINUS(오라클) EXCEPT(SQL) |
차집합 | |
| PRODUCT | CROSS JOIN | 곱집합(생길 수 있는 모든 데이터 조합) | |
| 관계 연산 | SELECT | WHERE절 | 조건에 맞는 행- 조회 |
| PROJECT | SELECT절 | 조건에 맞는 칼럼| 조회 | |
| JOIN | 여러 JOIN | ||
| DIVIDE | 없음 | 공통요소 추출하고 분모 릴레이션의 속성을 삭제한 후 중복된 행 제거 |
2. 조인 작성법
| WHERE절 | ON절(ANSI/ISO 표준) | USING절 | |
| 지원 구분 | Oracle O, SQL Server O | Oracle O, SQL Server O | Oracle O, SQL Server X |
| 표현되는 절 | WHERE절 | FROM절 | FROM절 |
| 연결칼럼명 | 연결하려는 두 테이블의 칼럼명 달라도 ㄱㅊ | 같아야 함 | |
| 추가조건 표현 |
JOIN 이후 AND/OR 연산자 통해 부수적인 조건 표현 가능 | JOIN은 FROM절에 표기되니 WHERE절에는 조건만 표기되어 구분하기 쉽다 |
|
| 유의사항 | WHERE절에서 JOIN과 다른 조건 구분하기 어렵 | EMP.DEPTNO 처럼 테이블명이나 별명 사용할 수 없다 | |
| 2개 테이블 JOIN |
SELECT 테이블A.칼럼명, 테이블B.칼럼명 FROM 테이블A, 테이블B WHERE 테이블A.칼럼명 = 테이블B.칼럼명; |
SELECT 테이블A.칼럼명, 테이블B.칼럼명 FROM 테이블A JOIN 테이블B ON 테이블A.칼럼명 = 테이블B.칼럼명; |
SELECT 칼럼명, 칼럼명 FROM 테이블 JOIN 테이블 USING (칼럼명); |
| 3개 테이블 이상 JOIN |
SELECT P.NAME, T.NAME, S.NAME FROM PLAYER P, TEAM T, STADIUM S WHERE P.PCODE = T.TCODE AND T.TCODE = S.SCODE; |
SELECT P.NAME, T.NAME, S.NAME FROM PLAYER P JOIN TEAM T ON P.PCODE = T.TCODE JOIN STADIUM S ON T.TCODE = S.SCODE; |
SELECT DEPTNO, EMPNO , DNAME, TNAME FROM EMP JOIN DEPT USING(DEPTNO) JOIN DEPT_TEST USING(DEPTNO); |
3. JOIN의 종류 : INNER / NATURAL / CROSS / LEFT [OUTER] JOIN / RIGHT [OUTER] JOIN / FULL [OUTER] JOIN
| 조인 종류 | INNER JOIN | NATURAL [INNER] JOIN | CROSS JOIN |
| 설명 | 테이블 간의 동일한 값 갖는 특정 칼럼 중 공통(=) 결과 보여준다(교집합) | 테이블 간의 동일한 이름, 값 갖는 모든 칼럼 중 공통(=) 결과를 보여준다(교집합) | 테이블 간의 모든 데이터의 조합 보여준다(M*N 데이터 조합) |
| 중복 출력 | 와일드카드(*) 사용 시 동일 값 칼럼 중복출력O(DEPTNO 2개) | 와일드카드(*) 사용 시 동일 이름, 값 칼럼 중복출력X(DEPTNO 1개) | 중복칼럼 존재 X |
| 지원 여부 | Oracle O, SQL Server O | Oracle O, SQL Server X | Oracle O, SQL Server O |
| 별명 가능 여부 | O (예외 : USING) | X | O |
| 조건 추가 여부 | WHERE절 조건 추가 가능 | WHERE절 조건 추가 X | WHERE절 조건 추가 가능 |
| 구현 방법 | WHERE, ON, USING절 | FROM절만 가능 SELECT * (DEPTNO, DNAME, LOC) FROM DEPT NATURAL JOIN DEPT_TEMP; |
FROM절만 가능 SELECT * FROM EMP CROSS JOIN DEPT; |
| 조인 종류 | LEFT [OUTER] JOIN | RIGHT [OUTER] JOIN | FULL [OUTER] JOIN |
| 설명 | - A와 B 조인시 A(왼쪽)를 모두 출력할 때 사용 - A와 매칭 안되는 B값은 NULL로 채운다 |
- A와 B조인 시 B(오른쪽)를 모두 출력할 때 사용 - B와 매칭 안되는 A값은 NULL로 채운다 |
- A와 B테이블 조인 시, A, B 모두 출력할 때 가용 - A와 매칭안되는 B값은 NULL로, B와 매칭안되는 A값은 NULL로 |
| 중복 출력 | 와일드카드(*) 사용 시 동일 값 칼럼 중복출력O(DEPTNO 2개) | ||
| 지원 여부 | Oracle O, SQL Server O | ||
| 별명 가능 여부 | O | ||
| 조건 추가 여부 | WHERE절 조건 추가 가능 | ||
| 구현 방법 | - FROM ON 절만 가능 SELECT S.NAME, T.NAME FROM STADIUM S LEFT JOIN TEAM T ON S.ID = T.ID; |
- FROM ON절만 가능 SELECT S.NAME, T.NAME FROM STADIUM S RIGHT JOIN TEAM T ON S.ID = T.ID; |
- FROM ON절만 가능 SELECT S.NAME, T.NAME FROM STADIUM S FULL JOIN TEAM T ON S.ID = T.ID; (LEFT JOIN UNION RIGHT JOIN과 같다) |


02 집합 연산자
1. 집합 연산자
- 조인을 사용하지 않고 연관된 데이터를 조회하는 방법
- 여러 SELECT문 결과를 연결해 하나로 결합하는 방식 사용
- SELECT문의 칼럼수가 동일하고 데이터타입이 상호호환되어야 한다.
| 종류 | 설명 | SQL기능 |
| UNION | 합집합. 두 집합 모두 표현 / 중복제거O / 정렬O | UNION |
| 합집합. 두 집합 모두 표현 / 중복제거X / 정렬X | UNION ALL | |
| INTERSECTION | 교집합. 두 집합의 공통집합 추출 / 중복제거O | INTERSECT |
| DIFERENCE | 차집합. 첫번째 집합에서 두번째 집합과의 공통부분 제외 / 중복제거O |
MINUS (MSSQL은 EXCEPT) |
| PRODUCT | 두 집합의 모둔 경우의 수 추출 / 중복 제거O | CROSS JOIN으로 구현됨 |
SELECT문
집합연산자
SELECT문
ORDER BY -- ORDER BY는 가장 마지막 줄에 한번만 기술
*차집합 다르게 표현하기 : MINUS / AND <> / AND NOT EXISTS / AND NOT IN
SELECT ~
FROM ~
WHERE 칼럼 연산자 조건1
MINUS
SELECT ~
FROM ~
WHERE 칼럼 연산자 조건2SELECT ~
FROM ~
WHERE 칼럼 연산자 조건1 AND 칼럼<> 조건2SELECT ~
FROM ~
WHERE 칼럼 연산자 조건 1
AND NOT EXISTS(
SELECT 1
FROM ~
WHERE 칼럼 연산자 조건2)SELECT ~
FROM ~
WHERE 칼럼 연산자 조건1
AND NOT IN (
SELECT 칼럼1
FROM ~
WHERE 칼럼 연산자 조건2)
*교집합 다르게 표현하기 : INTERSECT / AND / AND EXISTS / AND IN
SELECT ~
FROM ~
WHERE 칼럼 연산자 조건1
INTERSECT
SELECT ~
FROM ~
WHERE 칼럼 연산자 조건2SELECT ~
FROM ~
WHERE 칼럼 연산자 조건1
AND 칼럼 연산자 조건2SELECT ~
FROM ~
WHERE 칼럼 연산자 조건1
AND EXISTS (
SELECT 1
FROM ~
WHERE 칼럼 연산자 조건2)SELECT ~
FROM ~
WHERE 칼럼 연산자 조건1
AND IN (
SELECT 칼럼1
FROM ~
WHERE 칼럼 연산자 조건2)
2. 순수관계 연산자
| 종류 | 설명 | SQL 기능 |
| SELECT | 여러 행 중 조건에 맞는 수평적 부분집합 추출 | WHERE절로 구현 |
| PROJECT | 여러 열 중 조건에 맞는 수직적 부분집합 추출 | SELECT절로 구현 |
| JOIN | 다른 테이블과 공통속성 중심으로 새로운 집합 생성 | JOIN절로 구현 |
| DIVIDE | - | 사용되지 않음 |
03 계층형 질의와 셀프조인
1. 계층형 질의(Hierarchical Query) - Oracle만 지원함
▷ 계층형 질의 : 계층형 데이터 조회 방법
▷ 계층형 데이터 : 상하관계가 명확한 데이터
| 루트 노드 | 계층형 데이터의 최상위 노드. 부모 가지지 않음(아래 사진에서 A에 해당) |
| 형제 노드 | 같은 계층에 있는 데이터(아래 사진에서 B, C / D, E끼리 형제 노드) |
| 리프 노드 | 계층형 데이터의 최하위 노드. 자식을 가지지 않음(아래 사진에서 B, D, E에 해당) |
▷ 가상 칼럼과 함수
| 가상칼럼 | LEVEL | 순방향, 역방향 관계없이 루트를 1로 지정. 자식을 루트로 하면 부모는 2 (아래 사진에서 B가 루트이면 A는 2) |
| CONNECT_BY ISLEAF | 해당 칼럼이 리프노드이면 1, 아니면 0 반환 | |
| 함수 | SYS_CONNECT_BY_PATH(칼럼명, '구분자') | 루트부터 전개할 데이터까지의 경로를 표시한다. |
| CONNECT_BY_ROOT 칼럼 | 해당 칼럼의 루트데이터 표시 |
▷ 전개 방법
PRIOR = '이전의'라는 뜻을 가지고 있다. 상위 행의 값을 참조한다.
| 순방향 전개 | 역방향 전개 |
| 부모 = PRIOR 자식 | PRIOR 부모 = 자식 |
| 이전의 자식값 중에서 부모(기준값)을 찾는다 부모가 자식을 결정 |
이전의 부모값 중에서 자식(기준값)을 찾는다 자식이 부모를 결정 |



| 계층형 질의 | Oracle | |
| 구문 | SELECT ~ FROM ~ WHERE ~ START WITH 루트노드 지정조건 CONNECT BY [NOCYCLE] PRIOR 전개방향 조건 [ORDER SIBILINGS BY 칼럼명] - NOCYCLE : 상사가 꼬리에 꼬리를 무는 것 방지 - SIBILINGS BY : 형제들 정렬 기준 정의 |
|
| 예시 | SELECT CONNECT_BY_ROOT 사원 '루트', SYS_CONNECT_BY_PATH(사원, '/') '경로', LEVEL, 사원, 관리자 FROM 사원테이블 START WITH 사원='D' CONNECT BY PRIOR 관리자 = 사원; -- D를 루트로 지정하겠다 -- 사원이 관리자를 결정(역방향 전개) -- D와 연결된 C가 LEVEL 2로 오게 됨 -- C와 연결된 A가 LEVEL 3로 오게 됨 루트 경로 LEVEL 사원 관리자 ------------------------------------------------------- D /D 1 D C D /D/C 2 C A D /D/C/A 3 A |
SELECT CONNECT_BY_ROOT 사원 '루트' SYS_CONNECT_BY_PATH(사원, '/') '경로', LEVEL, 사원, 관리자 FROM 사원테이블 START WITH 관리자 IS NULL CONNECT BY PRIOR 사원=관리자; -- A를 루트로 지정하겠다. -- 관리자가 사원을 결정(순방향 전개) -- A와 연결된 B, C가 LEVEL 2로 오게 된다. -- C와 연결된 D, E가 LEVEL 3로 오게 된다. 루트 경로 LEVEL 사원 관리자 ------------------------------------------------------- A /A 1 A A /A/B 2 B A A /A/C 2 C A A /A/D 3 D C A /A/E 3 E C |
2. SQL Server 계층형 질의
: CTE(Common Table Expression)로 재귀 호출
3. 셀프 조인
: 동일 테이블 사이의 조인, ALIAS 필수
: 자신과 자신의 직속 상위행은 구할 수 있으나, 차상위행은 한번 더 셀프조인을 수행해야 구할 수 있다.
SELECT JU.J_ID 후배번호, JU.NAEMS 후배이름, SE.NAMES 선배이름
FROM STUDENTS JU
LFET OUTER JOIN STUDENTS SE
ON JU.S_ID = SE.J_ID
ORDER BY JU.J_ID;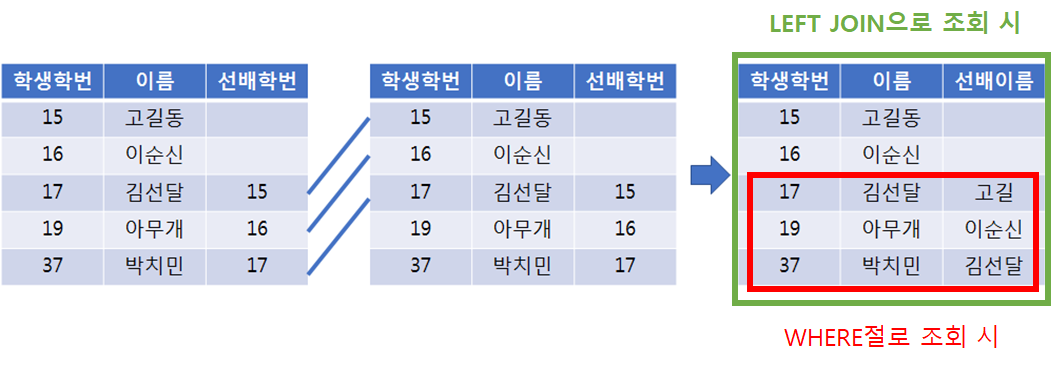
04 서브쿼리
1. 서브쿼리
: 하나의 SQL문 안에 포함된 또 다른 SQL문
: 서브쿼리는 괄호로 감싸서 사용하고, ORDER BY 는 메인쿼리에서만 사용할 수 있다.

2. 종류
▷ 반환값에 따른 분류
| 종류 | 단일 행 서브쿼리 | 다중 행 서브쿼리 | 다중 칼럼 서브쿼리 |
| 지원 | Oracle O, SQL Server O | Oracle O, SQL Server X | |
| 설명 | 서브쿼리 결과가 1건 이하 | 서브쿼리 결과가 2건 이상 | 서브쿼리 결과가 여러 칼럼 반환 메인쿼리의 조건과 비교될 때 사용 |
| 사용 가능 연산자 |
단일 행 비교연산자 =, <, <=, >=, >, <> |
다중 행 비교연산자 - 칼럼명 IN (서브쿼리) : 서브쿼리 결과 중 하나라도 일치하면 참 - 칼럼명 비교연산자 ALL(서브쿼리) : 결과 중 모든 값을 만족해야 함 - 칼럼명 비교연산자 ANY(서브쿼리) : 결과 중 하나라도 만족하면 참 - 칼럼명 EXISTS(서브쿼리) : 결과 중 값이 존재하면 참 |
|
| 예시 | Ally 선수가 소속된 팀 정보 SELECT * FROM PLAYER WHERE TEAM_ID = ( SELECT TEAM_ID FROM PLAYER WHERE PLAYER_NAME='Ally' ) |
Sam선수(동명이인)가 소속된 팀 정보 SELECT * FROM TEAM WHERE TEAM_ID IN( SELECT TEAM_ID FROM PLAYER WHERE PLAYER_NAME = 'Sam' ) --Sam1의 팀, Sam2의 팀 결과 출력 |
소속팀별 키가 가장 작은 사람의 정보 SELECT * FROM PLAYER WHERE (TEAM_ID, HEIGHT) IN( SELECT TEAM_ID, MIN(HEIGHT) FROM PLAYER GROUP BY TEAM_ID ) |
▷동작방식에 따른 분류
| 종류 | 동작방식 | |
| 연관 서브쿼리 | 비연관 서브쿼리 | |
| 설명 | - 메인쿼리의 칼럼을 서브쿼리에서 사용 - 메인쿼리의 결과를 서브쿼리에서 확인할 때 사용됨 - EXISTS 서브쿼리는 항상 연관 서브쿼리로 사용된다 |
- 메인쿼리의 칼럼을 서브쿼리에서 사용하지 않는다 - 메인쿼리에 값을 제공하기 위해 사용된다. |
| 예시 | 자신이 속한 팀의 평균키보다 작은 선수 정보 SELECT T.NAME , M.NAME , M.HEIGHT FROM PLAYER M, TEAM T WHERE M.TEAM_ID = T.TEAM_ID AND M.HEIGHT < ( SELECT AVG(S.HEIGHT) FROM PLAYER S WHERE S.TEAM_ID = M.TEAM_ID AND S.HEIGHT IS NOT NULL GROUP BY S.TEAM_ID ) |
|
▷ 사용위치에 따른 분류
| 종류 | 사용위치 | |
| 스칼라 서브쿼리(SELECT절에서 사용) | 인라인 뷰(FROM절에서 사용) | |
| 설명 | - 동적으로 생성된 임시칼럼처럼 사용가능 - 1행 1열만 반환하는 서브쿼리(단일 행 서브쿼리) - 메인쿼리의 결과 건수만큼 반복수행된다. |
- 동적으로 생성된 임시테이블처럼 사용가능 (조인방식 사용하는 것과 같음) - 테이블명 대신 사용가능 - 인라인 뷰 안에 ORDER BY를 사용해서 메인칼럼 실행 전에 미리 정렬 수행할 수 있다. |
| 예시 | 소속팀별 평균키를 행마다 출력 SELECT PLAYER_NAME, HEIGHT, ( SELECT AVG(HEIGHT) FROM PLAYER X WHERE X.TEAM_ID = P.TEAM_ID ) 평균키 FROM PLAYER P; |
포지션이 MF인 선수들의 정보출력 SELECT T.NAME, P.NAME FROM ( SELECT * FROM PLAYER WHERE POSITION = 'MF' ORDER BY ID) P , TEAM T WHERE P.ID = T.ID; |
3. 뷰 VIEW : 가상 테이블
실제 데이터를 가지고 있지 않지만 테이블의 역할을 수행할 수 있다. → 가상 테이블이라고도 함
▷ 뷰의 장점
| 독립성 | 테이블 구조 변경되어도 뷰를 사용하는 응용 프로그램은 변경하지 않아도 된다. |
| 편리성 | 복잡한 질의를 뷰로 생성하면 관련 질의를 편리하게 작성할 수 있다. |
| 보안성 | 뷰 생성 시 특정칼럼(급여정보..)를 빼고 생성해 정보를 감출 수 있다. |
▷ 뷰 사용방법
<생성>
CREATE VIEW 뷰이름 AS SELECT절;
<사용>(뷰를 사요하는 경우에 DBMS가 내부적으로 SQL문 재작성 함)
SELECT *
FROM 뷰이름;
=
SELECT *
FROM (SELECT절);
<삭제>
DROP VIEW 뷰이름;
4. WITH
: 서브쿼리를 이용하여 뷰로 사용할 수 있는 구문
WITH 뷰이름 AS (SELECT ~)05 그룹함수
1. ANSI/ISO 표준 데이터 분석 함수
: 집계 함수 , 그룹 함수, 윈도우 함수
2. 그룹 함수(Group Function)
| 다중행 함수 | Oracle | SQL Server | 설명 | |
| 집계 함수 | COUNT, SUM, AVG, MAX, MIN... | - 집계함수는 WHERE절에 사용X | ||
| 그룹함수 GROUP BY절에 사용함 |
계층 부분합 + 총합계 O |
ROLLUP(A, (B, C), D) = GROUP BY (A, (B, C), D) + GROUP BY (A, (B, C)) + GROUP BY (A) + GROUP BY () SELECT * FROM EMP, DEPT WHERE EMP.ID = DEPT.ID GROUP BY ROLLUP(DEPT.NAME, A.JOB); |
- 그룹별 합계와 총합계가 정렬되어 출력된다. - 매개변수를 오른쪽부터 빼서 GROUP을 만든다 - 매개변수는 계층구조이므로 순서가 바뀌면 결과도 바뀐다 |
|
| 계층 부분합 + 총합계 X |
GROUP BY A, ROLLUP(B, C) = GROUP BY (A, B, C) + GROUP BY (A, B) + GROUP BY (A) FROM EMP, DEPT WHERE EMP.ID = DEPT.ID GROUP BY DNAME, ROLLUP(JOB); |
- ROLLUP결과에서 총합계를 출력하지 않는다. | ||
| 모든 부분합 + 총합계 |
CUBE(A, (B, C), D) = GROUP BY (A, (B, C), D) + GROUP BY (A, (B, C) ) + GROUP BY ( (B, C), D) + GROUP BY (A, D) + GROUP BY (D) + GROUP BY ((B, C)) + GROUP BY (A) + GROUP BY () SELECT * FROM EMP, DEPT WHERE EMP.ID = DEPT.ID GROUP BY CUBE(DNAME, JOB); |
- 모든 경우의 수에 대한 그룹별 합계와 총합계가 출력된다. - 매개변수 순서가 달라져도 결과가 같다 - 시스템상 무리가 많이 가는 작업 |
||
| 개별 부분합 | GROUPING SETS(A, (B, C), D) = GROUP BY (A) + GROUP BY ((B, C)) + GROUP BY (D) SELECT * FROM EMP, DEPT WHERE EMP.ID = DEPT.ID GROUP BY GROUPING SETS(DNAME); |
- 그룹화한 SQL을 UNION한 것 과 같음 | ||
| 그룹핑 확인 | GROUPING(칼럼명) SELECT DENAME, GROUPING(DNAME) FROM DEPT GROUP BY ROLLUP(DNAME) |
- ROLLUP이나 CUBE에 의한 그룹별 합계는 1출력 - 그 외에는 0 출력(확인하기 위해 사용한다) |
||

06 윈도우 함수
1. 윈도우 함수(Window Function)
- 관계형 데이터베이스는 칼럼과 칼럼의 연산은 쉬운 반면 행과 행의 연산은 매우 어려웠다.
- PL/SQL, T-SQL 등의 절차형 프로그램을 작성하거나 INLINE VIEW로 해결해야했던 것을 함수로 쉽게 해결할 수 있다.
▷ WINDOWING절(SQL Server 지원X)
| 종류 | 의미 | 예제 |
| ROWS | 행 | |
| CURRNET ROW | 현재 행 | |
| RANGE | 칼럼 값 | |
| BETWEEN AND | 사이 값 | RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW 칼럼값을 제한없이 이하 값으로 현재 행의 |
| PRECEDING | 이전 행, 빼는 값 | ROWS 2 PRECEDING : 행의 2행 전 RANGE 2 PRECEDING : 칼럼값의 -2 |
| FOLLOWING | 다음 행, 더하는 값 | ROWS 2 FOLLOWING : 행의 2행 후 RANGE 2 FOLLOWING : 칼럼값의 +2 |
| UNBOUNDED | 제한 없음 | ROWS UNBOUNDED PRECEDING : 첫행~현재행까지 RANGE UNBOUNDED PRECEDING : 현재 칼럼값 이하 전부 |
| 윈도우 함수 | Oracle | SQL Server | |
| 순위 함수 |
공동순위 O 다음순위 연속수 X |
RANK() SELECT JOB, SAL , RANK() OVER (ORDER BY SAL DESC) , RANK() OVER (PARTITION BY JOB ORDER BY SAL DESC) FROM EMP; *공동 4위 다음 6위 |
|
| 공동순위 O 다음순위 연속수 O |
DENSE_RANK() SELECT JOB, SAL , RANK() OVER (ORDER BY SAL DESC) , DENSE_RANK() OVER (ORDER BY SAL DESC) FROM EMP; *공동 4위 다음 5위 |
||
| 공동순위X | ROW_NUMBER() SELECT JOB, SAL , RANK() OVER (ORDER BY SAL DESC) , ROW_NUMBER() OVER (ORDER BY SAL DESC) FROM EMP; *동일값 없음 |
||
| 순서 함수 |
파티션의 첫번째 값 |
FIRST_VALUE(칼럼명) SELECT DEPTNO, SAL, ENAME , FIRST_VALUE(ENAME) OVER (PARTITION BY DEPTNO ORDER BY SAL DESC) ROWS UNBOUNDED PRECEDING AS RICH //파티션의 첫 번째행~현재 행까지가 범위다 FROM EMP; *파티션 별 가장 먼저 나온 값 출력 |
지원 X |
| 파티션의 마지막 값 |
LAST_VALULE(칼럼명) SELECT DEPTNO, SAL, ENAME , LAST_VALUE(ENAME) OVER (PARTITION BY DEPTNO ORDER BY SAL DESC) ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING AS RICH //파티션의 현재 행~마지막 행까지가 범위이다 FROM EMP; *파티션 별 가장 나중에 나온 값 출력 |
||
| 이전 N행 값 | LAG(칼럼명, 이전N번째행, NULL인 경우 대체값) SELECT ENAME, HIREDATE, SAL LAG(SAL, 2, 10) OVER (ORDER BY HIREDATE) AS LAG_SAL FROM EMP; *파티션에서 이전 N번째 행의 값 가져올 수 있다. |
||
| 이후 N행 값 | LEAD(칼럼명, 이후N번쨰행, NULL인 경우 대체값) SELECT ENAME, HIREDATE, SAL , LEAD(SAL, 1, 10) OVER (ORDER BY HIREDATE) AS LEAD_SAL FROM EMP; *파티션에서 이후 N번째 행의 값 가져올 수 있다. |
||
| 윈도우 함수 | Oracle | SQL Server | |
| 비율 함수 |
파티션의 칼럼값/총합 |
RATIO_TO_REPORT(칼럼명) SELECT SAL , ROUND(RATIO_TO_REPRT(SAL) OVER (), 2) AS RT FROM EMP; SAL RT 1600 0.29 (1600/5600) 1250 0.22 (1250/5600) 1250 0.22 (1250/5600) 1500 0.27 (1500/5600) *행별 칼럼값의 비율을 0 이상, 1 이하의 수로 나타냄 *개별 RATIO의 합 구하면 1 |
지원X |
| 개별 백분율 첫 행 0 마지막 행 1 1/(칼럼수-1) 작은값 중복표기 결과 1행은 0 |
PERCENT_RANK() SELECT DEPTNO, ENAME, SAL , PERCENT_RANK() OVER (PARTITION BY DEPTNO ORDER BY SAL DESC) AS PR FROM EMP; *첫 행이 0이기 때문에 1/(칼럼수-1)가 결과 *마지막 행 1로 처리해 개별 백분율 구한다 *중복 값은 작은 값으로 중복 표기 *결과가 한 행밖에 없으면 0 출력 |
||
| 누적 백분율 마지막 행 1 1/칼럼수 큰값 중복표기 결과 1행은 1 |
CUME_DIST() SELECT DEPTNO, ENMAE, SAL , CUM_DIST() OVER (PARTITON BY DEPTNO ORDER BY SAL DESC) AS CD FROM EMP; *첫 행 지정값이 없기 때문에 1/(칼럼수)가 결과 *마지막 행 1로 처리해 누적 백분율 구함 *중복 값은 큰 값으로 중복 표기 *결과가 한 행 밖에 없다면 1 출력 |
||
| 그룹 N등분 나머지는 상위타일부터 균등하게 |
NTILE(N등분) SELECT SAL , NTILE(3) OVER (ORDER BY SAL DESC) FROM EMP; SAL NTILE 10 1 10 1 10 1 10 1 10 1 (5명을 3등분 : 1명(+1) + 1명(+1) + 1명) *그룹 N등분하고, 나머지는 균등하게 상위타일에 할당 |
||
Q. 다음 설명 중 적절한 것은?
① PARTITION과 GROUP BY구문은 의미적으로 완전히 다르다 // 유사하다
② SUM, MAX, MIN 등과 같은 집계 WINDOW FUNCTION을 사용할 때 WINDOW절과 함께 사용하면 집계의 대상이 되는 레코드 범위를 지정할 수 있다.
③ WINDOW FUNCTION처리로 인해 결과 건수가 줄어들 수 있다. //결과건수는 상관없다
④ GROUP BY 구문과 WINDOW FUNCTION은 병행하여 사용할 수 있다 //병행 불가
2. 윈도우 함수 문법
SELECT 윈도우함수명(매개변수) OVER(
[PARTITION BY 칼럼명] //GROUP BY 역할
[ORDER BY절] //ORDER BY 역할
[WINDOWING절] //WHERE역할, SQL Server지원X
)
FROM 테이블명;07 DCL
1. DCL : 유저 생성하거나 권한을 제어하는 명령어, 보안을 위해 필요
▷ GRANT : 권한 부여
GRANT 권한 ON 오브젝트 TO 유저명;
▷ REVOKE : 권한 제거
REVOKE 권한 ON 오브젝트 TO 유저명;
2. 권한
- SELECT, INSERT, UPDATE, DELETE, ALTER, ALL : DML 관련 권한
- REFERENCES : 지정된 테이블을 참조하는 제약조건을 생성하는 권한
- INDEX : 지정된 테이블에서 인덱스 생성하는 권한
3. Oracle 유저
- SCOTT : 테스트용 샘플 유저
- SYS : DBA 권한이 부여된 최상위 유저
- SYSTEM : DB의 모든 시스템 권한이 부여된 DBA
4. ROLE : 권한의 집합, 권한을 일일이 부여하지 않고 ROLE로 편리하게 여러 권한 부여할 수 있음
> Oracle의 ROLE
| ROLE | 권한 |
| CONNECT | CREATE SESSION |
| RESOURCE | CREATE CLUSTER CREATE TRIGGER CREATE PROCEDURE CREATE OPERATOR CREATE TYPE CREATE TABLE CREATE SEQUENCE CREATE INDEXTYPE |
08 절차형 SQL
1. 절차형 SQL
- SQL도 절차 지향적인 프로그램이 가능하도록 절차형 SQL을 제공하고 있다
- 연속적인 실행이나 조건에 따른 분기처리를 이용해 모듈 생성할 수 있다
- 저장모듈로 PROCEDURE, USER DEFINED FUNCTION, TRIGGER를 제공한다.
| 구분 | PROCEDURE 프로시저 | FUNCTION 함수 | TRIGGER 트리거 |
| 설명 | 특정 로직 처리 프로그램 | 특정 기능 처리 프로그램 | INSERT, UPDATE, DELETE 작업에 자동으로 실행되는 프로그램 |
| Oracle 구문 |
CREATE [or REPLACE] Procedure 프로시저명 (매개변수명 [MODE] 데이터 타입,...) IS [AS] 변수선언 BEGIN 실행내용 EXCEPTION 에러 발생 시 내용 END; / |
CREATE Function 함수명(매개변수명 데이터타입) RETURN 데이터타입 IS[AS] 변수선언 BEGIN 실행내용 RETURN 반환할 값 EXCEPTION 예외시 내용 END / |
CREATE Trigger 트리거명 BEFORE or AFTER INSERT or UPDATE or DELETE ON 테이블명 [FOR EACH ROW] [WHEN 조건식] 변수선언 BEGIN 실행내용 END / |
| SQL Server 구문 |
CREATE Procedure 프로시저명 @매개변수명 데이터타입 [MODE], .... AS 변수선언 BEGIN 실행내용 ERROR 에러 발생 시 내용 END; |
CREATE Function 함수명(매개변수명 데이터타입) RETURNS 데이터타입 AS 변수선언 BEGIN 실행내용 RETRUN 반환할 값 END |
CREATE Trigger 트리거명 ON 테이블명 FOR of AFTER or INSTEAD OF INSERT or UPDATE or DELETE AS 변수선언 BEGIN 실행내용 END; |
| 실행 방법 |
EXECUTE 프로시저명(매개변수) | 함수명(매개변수) | DBMS에 의해 자동실행 |
| RETURN | RETURN 필수X | RETURN 필수 O | 사용 안함 |
| TCL | BEGIN~END에 COMMIT, ROLLBACK 사용O |
BEGIN~END에 COMMIT, ROLLBACK 사용X |
2. 프로시저
| Oracle | SQL Server | |
| 절차형 SQL | PL(Procedural LAnguage)/SQL BLOCK 구조로 되어있어 각 기능별로 모듈화가 가능하다 |
T-SQL |
| Stored Procedure 생성방법 |
CREATE[or REPLACE] Procedure 프로시저명 (매개변수명[MODE] 데이터타입, .... ) IS [AS] 변수선언 BEGIN 실행할 내용 EXCEPTION 에러 발생 시 내용 END; / |
CREATE PRocedure 프로시저명 @매개변수명 데이터타입 [MODE], .... AS 변수선언 BEGIN 실행할 내용 ERROR 에러 발생 시 내용 END; |
| 매개변수 MODE - IN : 외부에서 매개변수 받을 때 사용 - OUT : 프로시저 결과 반환할 때 사용 - INOUT : IN과 OUT의 내용 동시 수행 / : 프로시저를 컴파일하도록 명령하는 것 |
매개변수 MODE - VARING : 결과 집합이 출력 매개변수로 사용되도록 - DEFAULT : 매개변수 값이 없으면 기본값으로 처리 - OUT/OUTPUT : 프로시저 결과 반환 - READONLY : 매개변수를 수정할 수 없다 |
|
| Stored Procedure 수정방법 |
REPLACE Procedure 프로시저명...을 작성하면 로운 내용으로 덮어쓰게 된다. |
ALTER Procedure....로 변경한다. |
| Stored Procedure 삭제방법 |
DROP Procedure 프로시저명; | DROP Procedure 프로시저명; |
| Stored Procedure 실행방법 |
EXECUTE 프로시저명(매개변수, ...); | EXECUTE 프로시저명 매개변수, ...; |
| 예제 | CREATE Procedure p_DEPT_insert ( v_DEPTNO in number, v_dname in varchar2, v_loc in varchar2, v_result out varchar2 ) IS cnt number := 0; --SCALAR 변수 cnt : 임시데이터 1개 저장가능 --대입연산자 := BEGIN SELECT COUNT(*) INTO CNT FROM DEPT --입력받은 부서코드가 존재하는지 확인 --SELECT문 결과가 반드시 있어야한다. WHERE DEPTNO = v_DEPTNO AND ROWNUM = 1; if cnt > 0 then --부서코드가 존재하면 v_result := '이미 등록된 부서번호이다'; else --부서코드가 존재하지 않으면 INSERT INTO DEPT (DEPTNO, DNAME, LOC) VALUES (v_DEPTNO, v_dname, v_loc); -- 레코드 입력 COMMIT; --커밋 v_result := '입력 완료!!'; end if; EXCEPTION --에러발생 시 WHEN OTHERS THEN ROLLBACK; v_result := 'ERROR 발생'; END; / |
CREATE Procedure dbo.p_DEPT_insert @v_DEPTNO int, @v_dname varchar(30), @v_loc varchar(30), @v_result varchar(100) OUTPUT AS DECLARE @cnt int -- 변수 선언 SET @cnt = 0 --SCALAR 변수 cnt : 임시데이터 1개 저장가능 --대입연산자 = BEGIN SELECT @cnt=COUNT(*) FROM DEPT --입력받은 부서코드가 존재하는지 확인 --SELECT문 결과가 없어도 된다. WHERE DEPTNO = @v_DEPTNO IF @cnt > 0 --부서코드가 존재하면 BEGIN SET @v_result = '이미 등록된 부서번호이다' RETURN END ELSE --부서코드가 존재하지 않으면 BEGIN BEGIN TRAN INSERT INTO DEPT (DEPTNO, DNAME, LOC) VALUES (@v_DEPTNO, @v_dname, @v_loc) -- 레코드 입력 IF @@ERROR<>0 BEGIN ROLLBACK --에러발생 시 SET @v_result = 'ERROR 발생' RETURN END ELSE BEGIN COMMIT --커밋 SET @v_result = '입력 완료!!' RETURN END END END |
3. 사용자 정의 함수
함수는 프로시저와 달리, RETURN을 이용해 값을 반드시 반환
| Oracle | SQL Server | |
| ABS 구현 예제 |
CREATE Function UTIL_ABS (v_input in number) return NUMBER IS v_return number := 0; BEGIN if v_input <0 then v_return := v_input * -1; else v_return := v_input; end if; RETURN v_return; END; / |
CREATE Function dbo.UTIL_ABS (@v_input int) RETURNS int AS BEGIN DECLARE @v_return int SET @v_return=0 IF @v_input <0 SET @v_return = @v_input * -1 ELSE SET @v_return = @v_input RETURN @v_return; END |
4. 트리거
- 특정 테이블에 INSERT, UPDATE, DELETE 등이 수행되었을 때, 데이터베이스에서 자동으로 동작하게하는 프로그램
- 트랜잭션 안에서 일어나는 작업으로 볼 수도 있다.
*ROLLBACK하면 트리거 작업내역도 모두 취소된다.
| Oracle | SQL Server | |
| 예제 | CREATE Trigger SUMMARY_SALES AFTER INSERT --레코드가 입력된 후 트리거실행 ON ORDER_LIST -- 테이블에 트리거 설정 FOR EACH ROW --각 행마다 트리거 실행 DECLARE o_date ORDER_LIST.order_date%TYPE; o_prod ORDER_LIST.product%TYPE; BEGIN o_date := :NEW.order_date; --NEW 신규행의 정보 o_prod := :NEW.product; UPDATE SALES_PER_DATE SET qty = qty + :NEW.qty, amount = amount + :NEW.amount WHERE sale_date = o_date AND product = o_prod; if SQL%NOTFOUND then INSERT INTO SALES_PER_DATE VALUES(o_date, o_prod, :NEW.qty, :NEW.amount); end if; END; / |
CREATE Trigger dbo.SUMMARY_SALES ON ORDER_LIST -- 테이블에 트리거 설정 AFTER INSERT --레코드가 입력된 후 트리거실행 AS DECLARE @o_date DATETIME,@o_prod INT, @qty int, @amount int BEGIN SELECT @o_date=order_date, @o_prod=product, @qty=qty, @amount=amount FROM inserted -- inserted 신규행의 정보 UPDATE SALES_PER_DATE SET qty = qty + @qty, amount = amount + @amount WHERE sale_date = @o_date AND product = @o_prod; IF @@ROWCOUNT=0 INSERT INTO SALES_PER_DATE VALUES(@o_date, @o_prod, @qty, @amount) END |